Persistent Agent Memory
Give every agent a long-term store that outlives the context window. Facts, users, and workflows persist across sessions instead of resetting with each new chat.
mechanism: Neo4j graph, agent-namespaced
Self-hosted · MCP-native · Open source
Self-hosted, MCP-native memory for AI agents. One command drops SpAIder into Claude Code, Cursor, or any MCP client — your agents read and write a private knowledge graph instead of re-asking you every morning.
v0.1.0 · self-host only today · AGPL-3.0 core
Why agents forget
Every new chat is a blank room. You re-paste the same context, the same docs, the same project background. The agent doesn't carry yesterday into today.
Your company's facts — accounts, contracts, internal decisions — are nowhere in the model's training. Pasting them in works once, until the context window or your token bill stops it.
Anything the agent figures out in one session is lost in the next. There's no place for it to remember "we decided X, because Y."
The Five Pillars
Give every agent a long-term store that outlives the context window. Facts, users, and workflows persist across sessions instead of resetting with each new chat.
mechanism: Neo4j graph, agent-namespaced
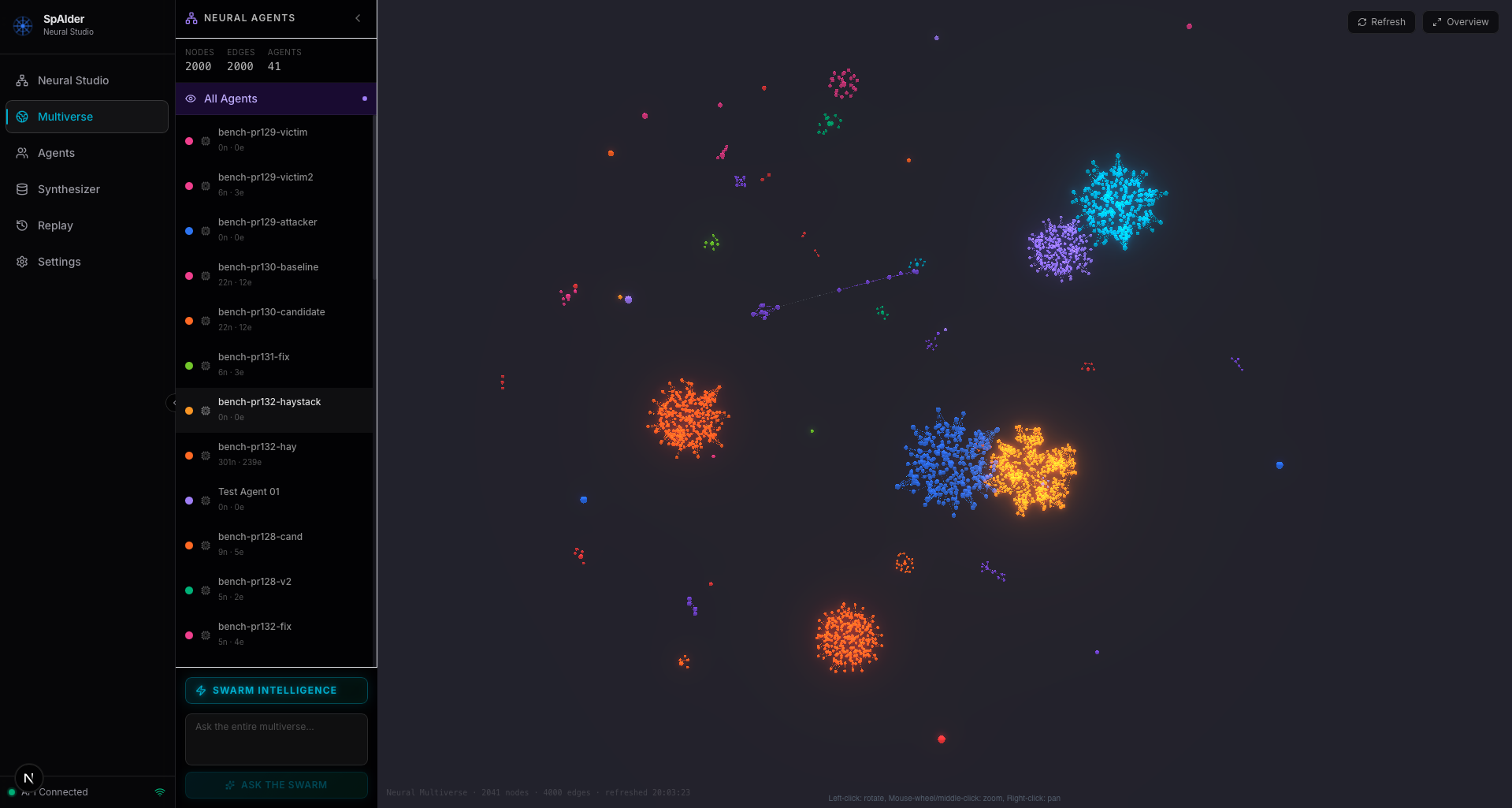
Route multiple agents into one memory graph so they share context and knowledge in real time, instead of each keeping a private silo.
mechanism: /swarm endpoint · Redis Streams (stigmergic)
{
"mcpServers": {
"spaider": {
"command": "spaider-mcp",
"args": ["--port", "8080"]
}
}
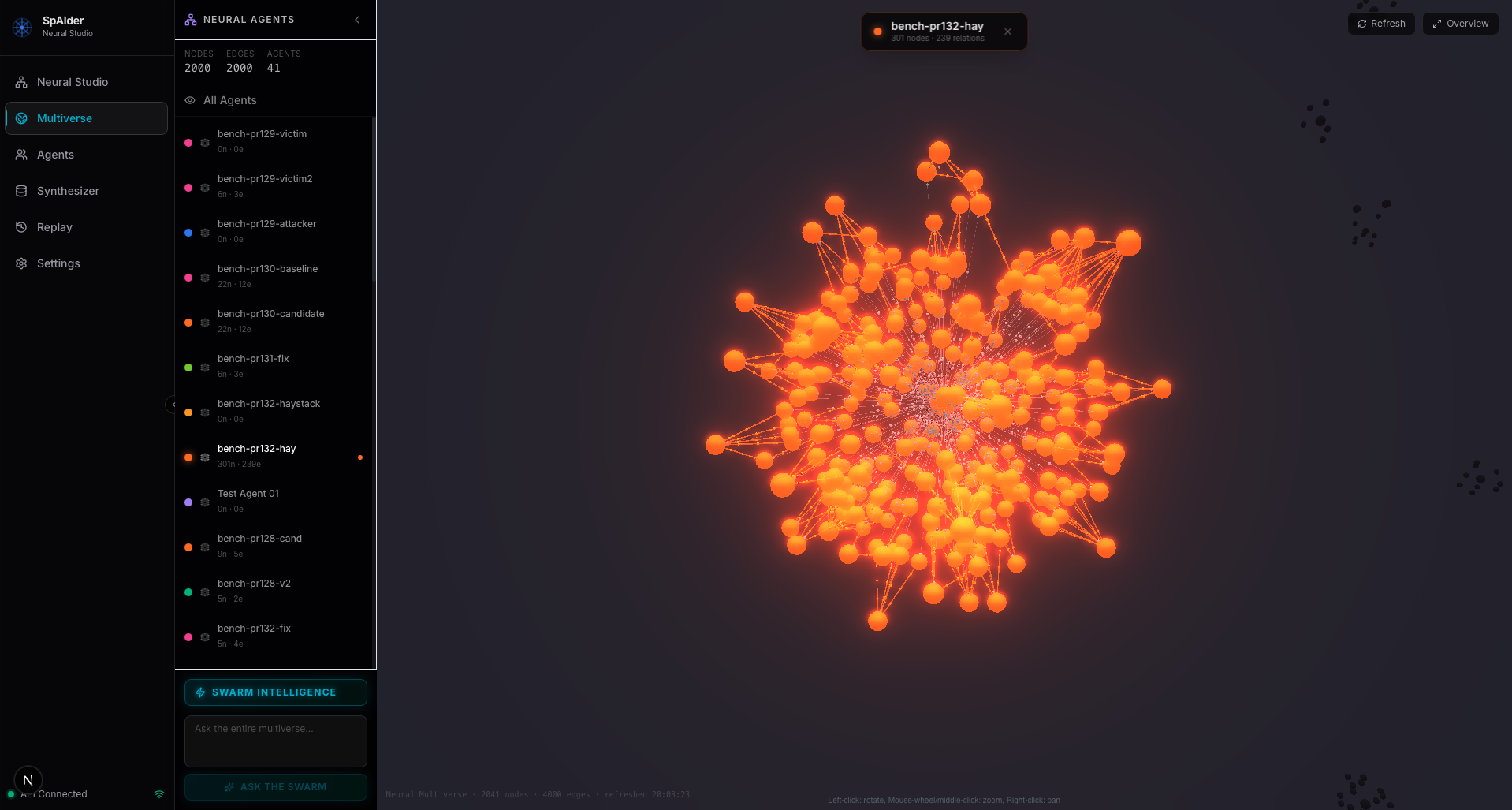
}Inspect and audit what every agent knows from a single view. A live graph shows the entities and relations each agent has stored, and how they connect.
mechanism: Next.js 3D Force Graph (WebGL)
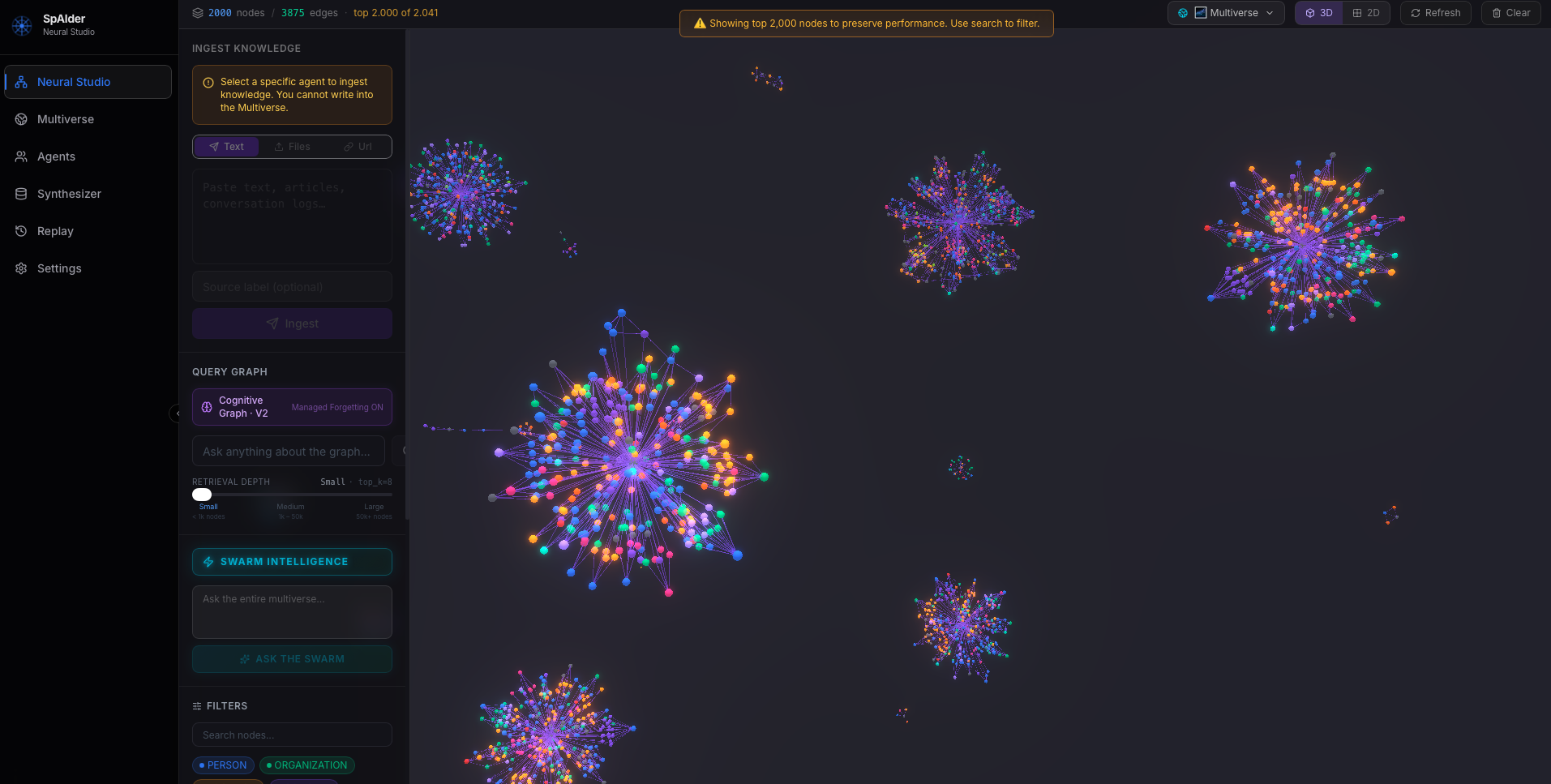
Raw documents go in; a structured, queryable graph comes out. SpAIder extracts entities and relations so you don't hand-build the schema.
mechanism: SemanticCompressor (LLM) + EntityResolver
Export the graph straight to JSONL and fine-tune your own open-source models on real, structured company knowledge — entirely on your infrastructure.
mechanism: /synthesize → training.jsonl on your filesystem
pipx install ./cli, then spaider init. Native to Claude Code, Cursor, and any MCP client.The honest battle card
Mem0 has the largest ecosystem and a true managed cloud. If you want zero-ops vector-first memory and you're fine sending data to their infrastructure, Mem0 is the obvious pick. SpAIder is for teams who want the graph itself running on their own machines.
Zep has SOC 2 and one of the strongest published LongMemEval scores in the open ecosystem; it's mature. SpAIder is younger and uncertified. What SpAIder gives you that Zep doesn't, today, is a one-command MCP install and a Claude Code skill file that ships in the box.
Cognee is the closest neighbor: graph from unstructured docs, self-hostable. SpAIder differs on two axes — it's MCP-native by default, and the CLI provisions an agent + writes the skill file, so the loop from git clone to "Claude Code uses it on its own" is one command.
Honestly fine for a solo project. It stops scaling the moment two agents need to share memory, or the same fact needs to be retrieved by meaning rather than by filename.
Reflexive, not just available
spaider init provisions an agent, writes ~/.claude/.mcp.json, and writes ~/.claude/skills/spaider.md — a skill file that tells the model when to call each tool.
git clone https://github.com/Spaider-studio/spaider.git cd spaider pipx install ./cli spaider init # provisions agent + writes MCP config + skill file # restart Claude Code
In a fresh session, ask “what do you remember about this project?” — Claude reaches for spaider.list_recent and spaider.query on its own. Capture a fact with spaider.ingest_fact; rate an answer with spaider.feedback.
The MCP server gives Claude tools. The skill file gives Claude reflexes.
The same spaider init flow works in Cursor and any MCP client. Claude Code is the most polished today because the skill file ships in the box.
Calibrated, not vibes
You could reach the same accuracy by pasting your whole knowledge base into every prompt — until the bill compounds and the request stops fitting in the model’s context window. SpAIder retrieves a bounded subgraph instead, so the tokens injected per query stay roughly flat; context-stuffing crosses SpAIder at around 15k tokens and hard-fails above ~30k.
Measured on gpt-4o-mini with default retrieval bounds. See docs/token-economics.md.
Accuracy
| Metric | HotpotQA (public — model has seen it) | AcmeAI (private — model has not) |
|---|---|---|
| GEval (gpt-4o judge) | 0.43 → 0.77 | 0.00 → 0.97 |
| F1 | 0.09 → 0.70 | 0.00 → 0.78 |
| Exact Match | 0.00 → 0.52 | 0.00 → 0.72 |
For the eng lead approving this
docker compose up -d brings the whole thing up.Licensing & ownership
Backend server + frontend
AGPL-3.0
Self-host freely. Run a modified version as a network service and you owe your changes back to the project under AGPL.
CLI + Python SDK
Apache-2.0
Embed in any application, closed or open, without copyleft obligations.
Commercial license
Available
If AGPL's publish-modified-source requirement is a blocker, write to contact@spaider.studio. This licenses the software; it is not a managed hosted offering.
SpAIder runs on your infrastructure. Your data and the graph stay on your machines. Fine-tuning JSONL exports (/synthesize) are written to your filesystem, never sent to a third party.
Install now
pipx install ./cli && spaider init. The repo is github.com/Spaider-studio/spaider. Open an issue with what breaks — we answer every one.
Read first
Benchmarks: benchmarks/COMPARISON.md. Architecture and operations: docs/operations.md. Read first, install second — that’s fine with us.
Talk to the builders
contact@spaider.studio, or . We’re early — you can shape the roadmap.
Security disclosures: security@spaider.studio.